Sentiment Bias In Transgender News Coverage
LINKS
You can find the relevant GitHub code at github.com/aashish-mehta/sentiment-analysis. Here, you can find many methods for pre-processing text and performing NLP methods. There is also a Jupyter notebook which you can follow along with to do the sentiment analysis for yourself.
SUMMARY
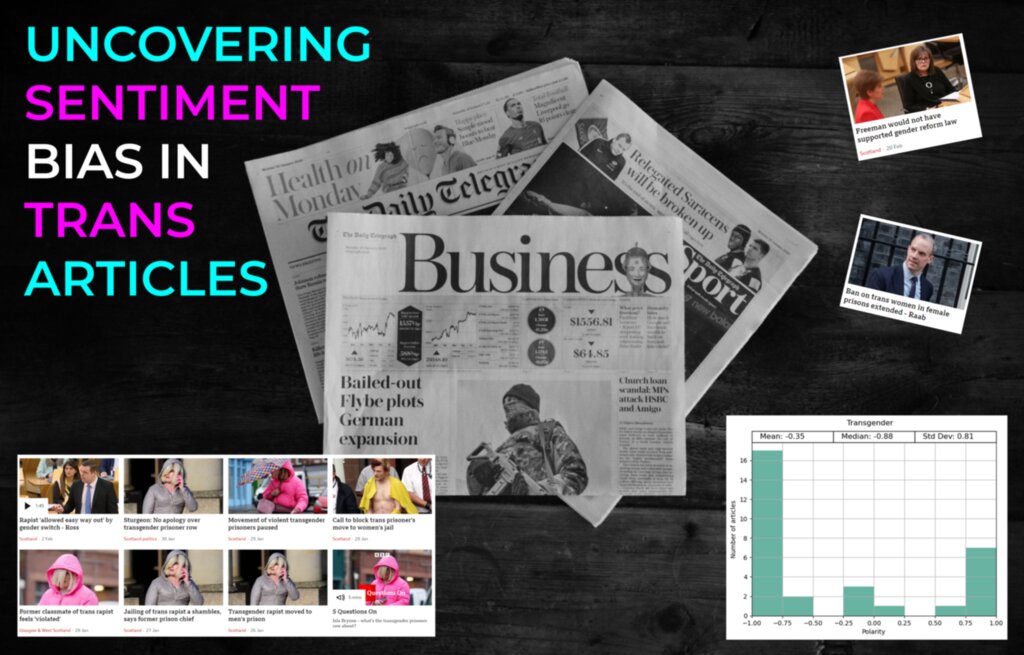
In this article, we explore the sentiment of transgender news coverage from multiple sources. Using the Vader sentiment analysis tool, it was found that over two-thirds of transgender-related articles from the BBC had a strong negative sentiment. To confirm the validity of our analysis, we used uplifting and disaster topics as references.
In contrast, Pink News, an LGBTQ-centric news source, had around 75% positive articles on transgender news topics.
BBC
PINK NEWS
Having so many negative stories about a particular topic will naturally cause the reader to develop a link that they are perhaps not even aware of. This can be extremely harmful, as it shapes the way the public reacts to transgender issues. These findings underscore the significance of reading news from multiple sources and being aware of the overall sentiment of the articles you are consuming.
CONTENTS
INTRODUCTION
I recently made a smart mirror for my living room, and it’s pretty useful! I can set it to show me my calendar, the weather and my list of things to do. I can also set it to fetch the latest headlines from a news website, like BBC News. For the first few weeks, I’d come home from work, check the mirror, get all the updates I needed, and go on with my day.

Over time, I noticed a big increase in the number of headlines on transgender people – I’m talking at least once a day. That seemed strange, given that only ~0.5% of people in the UK identify as transgender. But hey, more recognition in the media isn’t always a bad thing, right? Well, after reading every one of those headlines, I was left with an awful knot in my stomach – the news was rarely ever ‘good’. It got to a point where I’d come home, look in the mirror and check ‘What controversy has my existence caused today, BBC overlords?’ Sure enough, they’d answer, ‘Well I’m glad you asked … !’
So that got me thinking, why is it that I’ve learned to dread any mention of transgender news? How can I even explain this ‘feeling’ to someone else, who might not be so directly affected?
Fortunately, the amazing advances in Natural Language Processing have allowed us to view and analyse feelings, or ‘sentiment’, as data. In another post, I analysed a few different NLP Sentiment Analysis tools and found that VADER (accessed through NLTK) gave the best results for analysing news articles. In this post, I will be using VADER, along with a BeautifulSoup-powered scraper, to analyse news articles from various topics and sources. This includes, of course, transgender news articles from the BBC.
DETAILS
Every piece of code I used to generate these results can be found in my Jupyter notebook. Feel free to code along, or play around with it and see if you find some interesting results of your own!
In the first cell, we download some of the datasets used in this analysis if you haven’t got them already (read more about installing NLTK Data).
import nltk
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('vader_lexicon')Next, we define a method to gather all of the articles we will be analysing given our news source and topic. We can also specify the number of pages we’d like to extract the articles from (e.g. each page might have ~20 articles).
This assumes whatever news site we’re extracting from follows the multi-page standard of having ?page=n at the end of their URL. This is true for most of the sites we’re looking at, including BBC News. If this is not the case (e.g. for Pink News), that’s fine. The code will still work, it will just analyse the first page of articles.
from modules.article_retriever import get_articles_for_topic
def get_article_urls(source, topic, number_of_pages = 1):
url_list = []
for i in range(number_of_pages):
suffix = '' if i == 0 else f'?page={i}'
url_list += get_articles_for_topic(source, topic, suffix)
return url_listNow we can define our topic and news source. You can see all of the options in common/enum.py, and some definitions in config.ini.
Using this and our above method, we get a list of article URLs ready to be scraped and analysed.
from common.enum import NewsSource, Topic
topic = Topic.TRANSGENDER # Transgender News
source = NewsSource.BBC
number_of_pages = 4
url_list = get_article_urls(source, topic, number_of_pages)
article_count = len(url_list)
print(article_count, 'article(s) found')Next, we can loop over the list, and use a method I wrote under modules/article_retriever to extract the text. Using some more methods under modules/preprocessing and modules/sentiment_analysis, we can clean and process the text to get some polarity values.
from modules.article_retriever import extract_article_info
from modules.preprocessing import preprocess_text
from modules.sentiment_analysis import get_polarity, SentimentMethod
article_sentiments = []
for i, url in enumerate(url_list):
[header, article_text] = extract_article_info(url, source)
if not article_text:
print(f"No text in article {i+1} ({url})")
continue
article_polarity = get_polarity(preprocess_text(article_text), SentimentMethod.VADER)
article_sentiments.append({'header': header, 'polarity': article_polarity, 'url': url})
print(f"Article {i+1}/{article_count} processed")To make the data easier to access and visualise, we turn it into a pandas dataframe (essentially a table). This dataframe is also the expected data format for the methods I wrote in modules/plot_methods.
from modules.plot_methods import create_dataframe
sentiment_df = create_dataframe(article_sentiments)
sentiment_df.name = topic.value.replace('_', ' ').title()
print(sentiment_df[['header', 'polarity']])Finally, we can generate some histograms. I find these to be a useful way to view polarity, which can only vary between -1 and 1 and is usually quite distinct.
from modules.plot_methods import display_histogram
display_histogram(sentiment_df)RESULTS
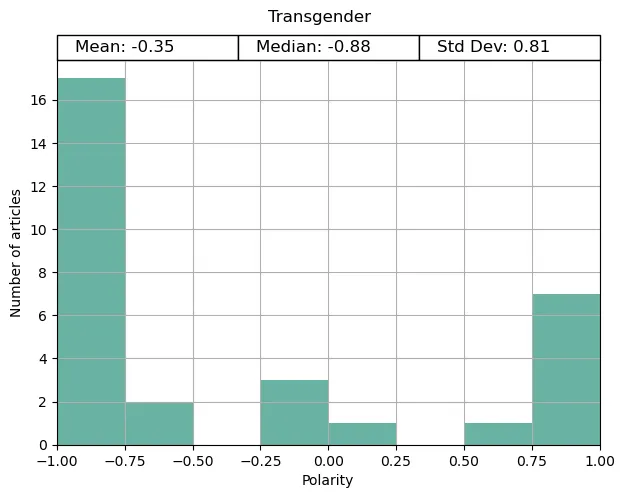
When the code was run for the post (early April 2023), I found that over two-thirds of articles from BBC News on the ‘Transgender People’ topic were significantly negative.
To confirm the validity of the Transgender News analysis, I used two reference topics for which we can safely assume what the polarity would be. Uplifting news (for positive results), and Severe weather / disaster (for negative results). You can find links to all of the topics I used in the config.ini file.
The result from our analysis is exactly as you would expect. The vast majority of articles in the disaster topic had a negative polarity, and most of the uplifting articles were positive. Based on this, we can have some faith in the results of our analysis.
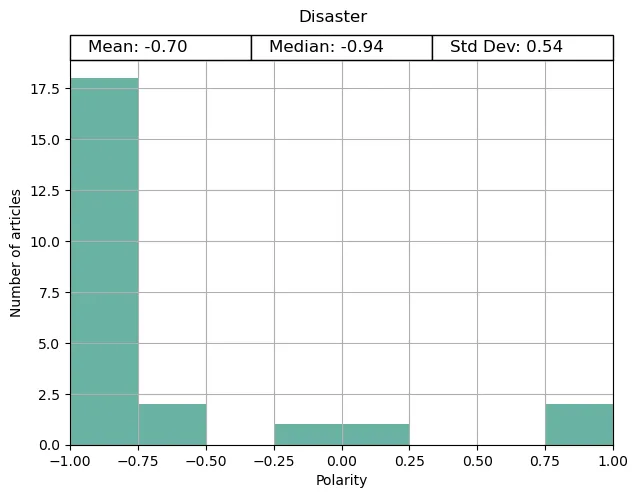
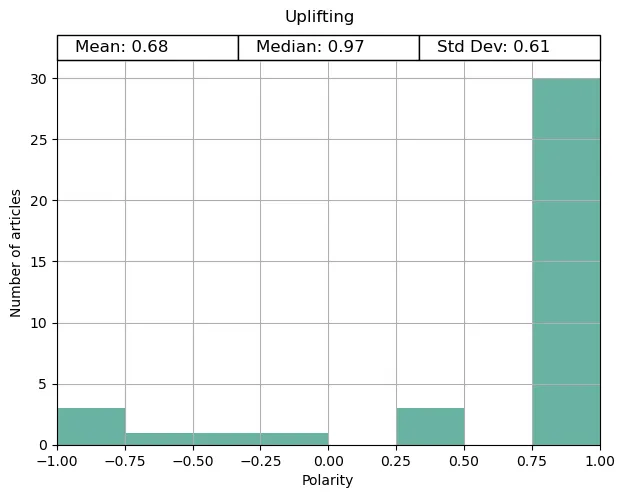
Generally speaking, if most articles on a topic are negative, the public’s perception will match that sentiment. After all, if someone were to preface their story as a ‘disaster’, you wouldn’t be overly optimistic about it. What is your initial feeling when someone says they want to talk about transgender news or trans people?
Of course, a piece of text with a negative sentiment doesn’t inherently mean malice. For example, there might be articles exposing intolerance or bigotry, and the sentiment may be negative towards those stances.
Looking at the ‘Transgender people’ topic in more detail, we can almost immediately see the negative headlines. One clear example is the barrage of consecutive articles around a transgender prisoner over a two-week period near the end of January 2023. Not a single article on anything else was posted on the transgender news topic during this time.
Something is very clearly wrong in the BBC’s coverage of transgender news.
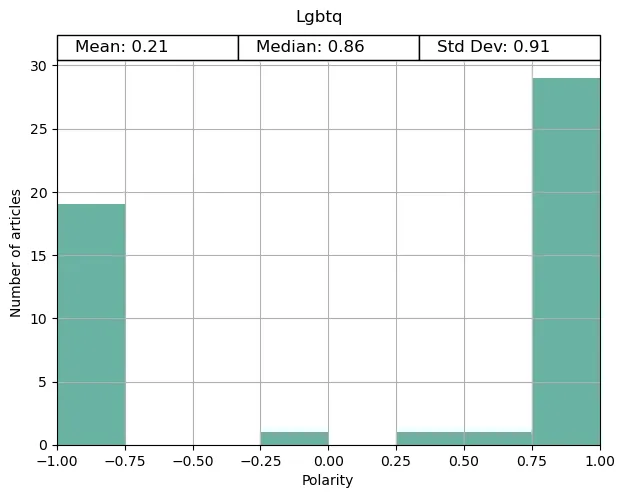
For comparison, we can also have a look at the coverage of LGBTQ news in general (another topic you can select if you’re following along).
The results of this were slightly more positive. This is closer to what I would expect from the primary news source of a country that claims to promote diversity and tolerance.
I thought it might also be useful to compare the BBC to some other news sources, like Pink News (an LGBTQ-centric source), the Guardian, and VICE. I will present the results for their Transgender news and LGBTQ topics below. Remember, you can do this analysis yourself for any of these sources on any of the topics specified (you can even add your own if you’re feeling adventurous!).
Pink News had the highest proportion of positive articles for the Transgender news topic, as well as for LGBTQ articles in general. This was unsurprising, given the general content and aim of the news site.
The Guardian had a fairly even split of positive and negative coverage on trans topics but was significantly negative on LGBTQ articles. Digging a little deeper into this reveals that many of these articles were exposing bigotry (e.g. ‘What’s behind the ‘terrifying’ backlash against Australia’s queer community?‘ and ‘Sydney MP pushes for new protections for LGBTQ+ people after ‘hurtful’ tweet‘). Nonetheless, it is a reminder of the ongoing struggles faced by the community around the world.
Finally, VICE managed to remain fairly neutral with its split between the two topics.
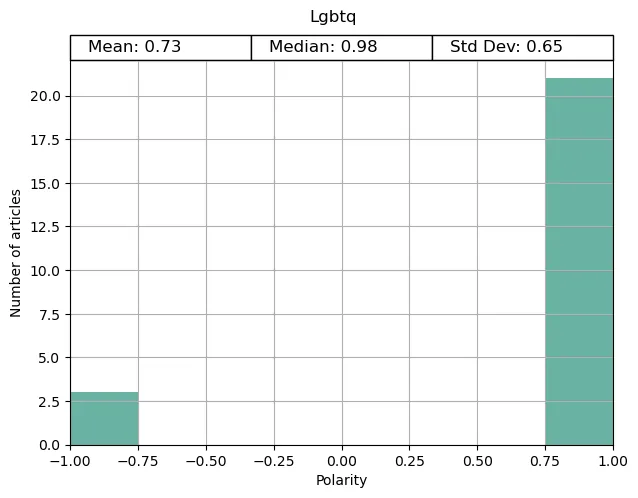
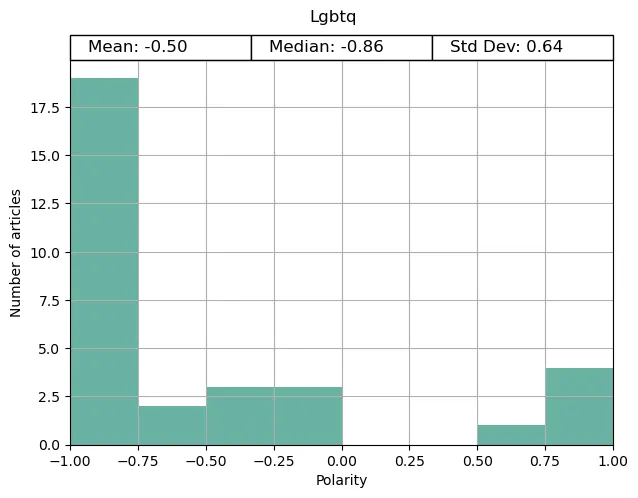
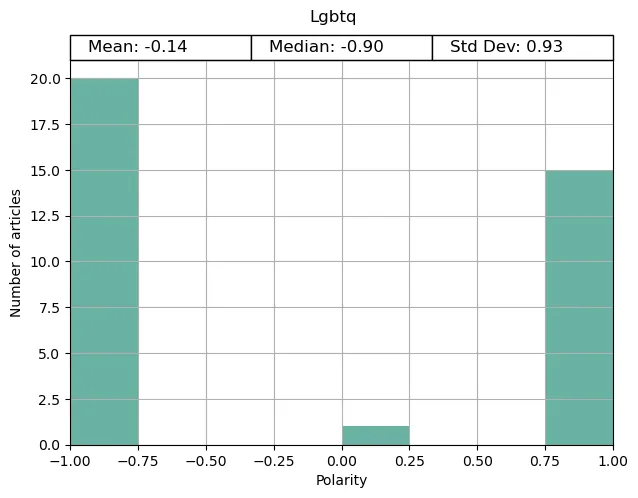
(Although I do question VICE’s choices for the articles in their topics when they have this under ‘good news’ … )

CONCLUSION
Thank you for reading my post! I hope this has made you aware of some of the subtle, yet significant ways in which media can negatively affect how certain topics might be perceived. I encourage you to try and get your news from a variety of sources, and to consider what kind of emotions the articles you read are trying to elicit.
Remember, spreading positive news is an easy, powerful way to make people in the LGBTQ community more comfortable, and can break that innate, awful feeling whenever someone brings up the topic.