Sentiment analysis comparison for three NLP tools
LINKS
You can find the relevant GitHub code at github.com/aashish-mehta/sentiment-analysis. Here, you can find many methods for pre-processing text and performing NLP methods. There is also a Jupyter notebook which you can follow along with to do the sentiment analysis comparison for yourself.
Other repositories of interest are TextBlob NLTK, and Flair. You can read more about each method at their respective sites.
ABSTRACT
A sentiment analysis comparison between the three methods was conducted for a set of articles (uplifting, and disaster related), and reviews (positive and negative).
For the articles, Vader analysed almost every piece of text correctly. Flair and TextBlob did not give decisive results.
For the reviews, Vader struggled with the negative datasets, while Flair correctly analysed both the positive and negative texts. TextBlob struggled with both.
The conclusion is that Vader seems more suitable for longer more formal pieces of text such as news articles. Flair gave better results for shorter, informal datasets like customer reviews. TextBlob was quick to implement, but was outperformed by the other two methods.
INTRODUCTION
SENTIMENT ANALYSIS COMPARISON
Sentiment analysis, also known as opinion mining, is a technique used to extract and analyze subjective information from text data.
It can be a very useful tool to make data-driven decisions, and to develop a formal understanding of the ‘feeling’ a piece of text elicits . With the increasing amount of text data available online, sentiment analysis tools have become more sophisticated, accurate and accessible.
In this article, we will compare three popular sentiment analysis tools: TextBlob, VADER, and Flair. Each of these tools uses a different approach to sentiment analysis and has unique features and advantages.
VADER | FLAIR | TEXTBLOB
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon and rule-based sentiment analysis tool that is specifically designed to handle social media texts. It uses a sentiment lexicon that is trained on social media data and incorporates rules that handle sentiment intensity, negation, and punctuation.
Flair is a text embedding library that provides state-of-the-art models for named entity recognition, part-of-speech tagging, and sentiment analysis. It uses a deep learning approach and incorporates contextual information to improve the accuracy of its predictions.
TextBlob is a Python library that provides a simple API for sentiment analysis, part-of-speech tagging, and noun phrase extraction. It uses a rule-based approach and a machine learning model to analyze text data.
To evaluate the performance of each tool, we will use a dataset of reviews and news articles and compare the results of each tool’s sentiment analysis. By the end of this article, you will have a better understanding of the strengths and weaknesses of each tool and which one is best suited for your sentiment analysis needs.
METHOD
I used a Jupyter notebook, polarity-comparison.ipynb, for the code used to compare the different sentiment analysis methods.
In the first cell, we download some of the datasets used in this analysis if you haven’t already (read more about installing NLTK Data)
import nltk
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('vader_lexicon')The article and review data files are placed in the data/ directory. The positive and negative articles were taken from BBC’s Uplifting and Disaster topics respectively. The review data was taken from EatSleepWander’s positive review examples, and negative review examples.
Consequently, the next cell introduces two simple methods to help retrieve the text. The first returns the correct folder for each source (e.g. Article or Review) and the topic (e.g. Positive or Negative). The second will use a full filepath to a text file and return its contents.
import os
def get_folder(source, topic):
return f'data/{source.value}/{topic.value}'
def get_text_from_file(filepath):
with open(filepath, 'r') as f:
text = f.read()
return textNext, we can define the method to get the sentiments from the text. I have placed all of the core logic in the modules/ directory. In this notebook, we first use the pre-processing methods to remove stopwords, and lemmatise words before we analyse it.
Whether this is required or not really depends on the tool – some will take into account neutral words like ‘and’ or ‘that’ and weigh them much lower for the final score. For others, I find that it heavily dilutes the overall polarity score. If you are interested, I would reccomend playing around with this cell, and the preprocess_text method, and seeing how the results differ.
The method will take in the source, topic and sentiment method we want to use. It will use our helper functions we defined earlier to extract each text file that matches the source and topic. The polarity analysis is handled by the module code I’ve written for each sentiment method in modules/sentiment_analysis.py.
The output of this method is a data structure with header and polarity fields for each article found.
from modules.preprocessing import preprocess_text
from modules.sentiment_analysis import get_polarity
def get_sentiments_from_text(source, topic, sentiment_method):
folder_path = get_folder(source, topic)
sentiments = []
for filename in os.listdir(folder_path):
text = get_text_from_file(os.path.join(folder_path, filename))
article_polarity = get_polarity(preprocess_text(text), sentiment_method)
sentiments.append({'header': filename, 'polarity': article_polarity})
return sentimentsNow let’s see the results! The final code block is where we actually define the text type and source we want to view. We loop over all of the sentiment analysis methods we have defined in common/enum.SentimentMethod and extract the sentiment for each text of our text files using the get_sentiments_from_text method we defined earlier.
We can then can store the results in a pandas dataframe, and use it with modules/plot_methods.py. I find a histogram is a create way to visualise sentiment, since they generally range from -1 to 1.
from matplotlib import pyplot as plt
from common.enum import *
from modules.plot_methods import create_dataframe, display_histogram
textType = TextType.NEGATIVE
textSource = TextSource.ARTICLES
for method in SentimentMethod:
sentiments = get_sentiments_from_text(textSource, textType, method)
sentiment_df = create_dataframe(sentiments)
sentiment_df.name = f'{textType.value} {textSource.value} ({method.value})'.title()
display_histogram(sentiment_df)
#plt.savefig(f'{method.value}-{textSource.value}-{textType.value}.webp')RESULTS
ARTICLES | Sentiment Analysis Comparison
First, lets look at how each method performed for the BBC articles.
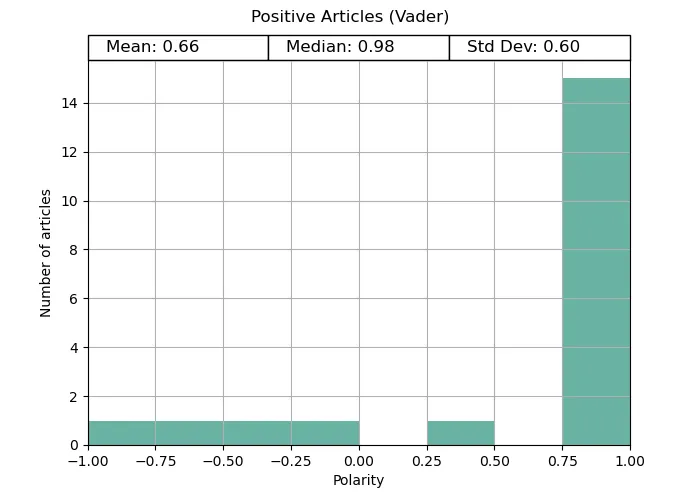
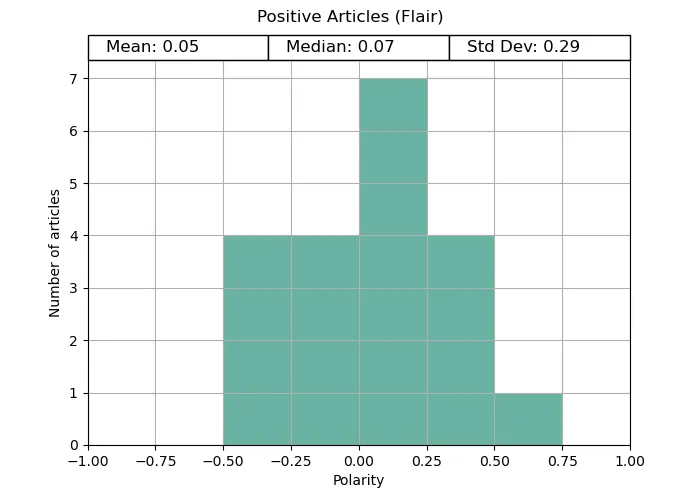
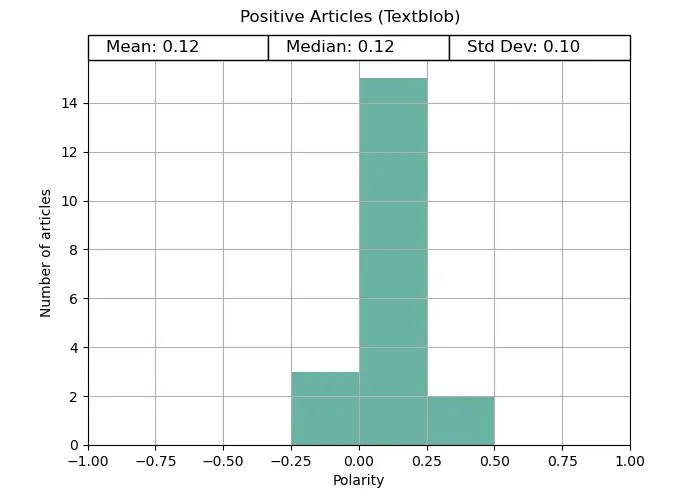
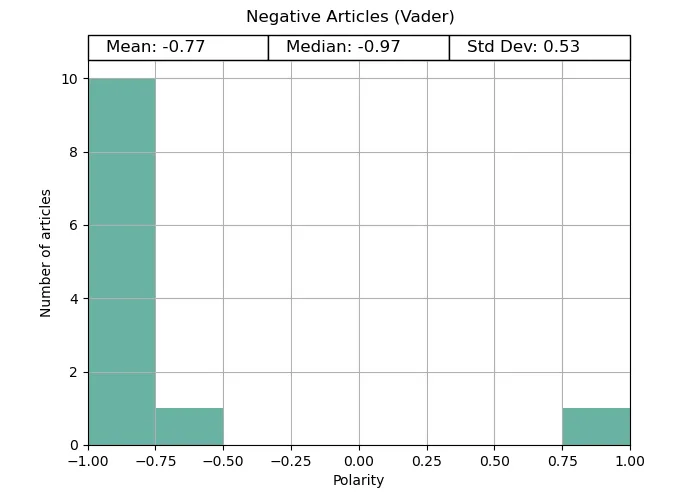
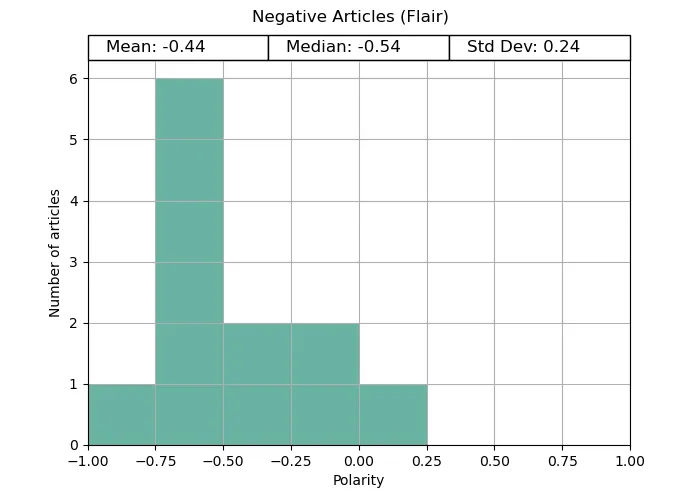
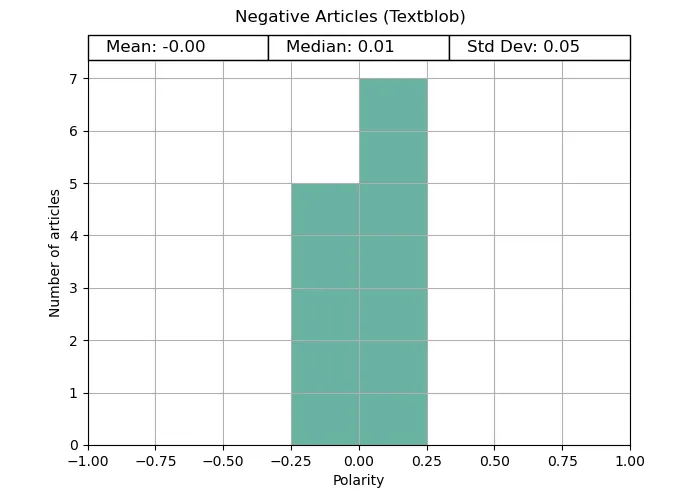
In both the positive and negative tests, Vader provides distinctive polarities matching what we would expect; positive for uplifting news, and negative for disaster news. Both ends are quite extreme, potentially due to the way the compound scores are calculated. Vader was made to be distinct in its answer.
Flar provided expected results for the disaster articles, but stayed close to the average for its uplifting counterpart. Both cases were not nearly as extreme as Vader, possibly owing to its emphasis on context awareness, and using the entire text throughout its analysis.
On the other hand, TextBlob struggled completely to provide a significant polarity, despite the pre-processing.
REVIEWS | Sentiment Analysis Comparison
Next, lets see if the results for the reviews are any different.
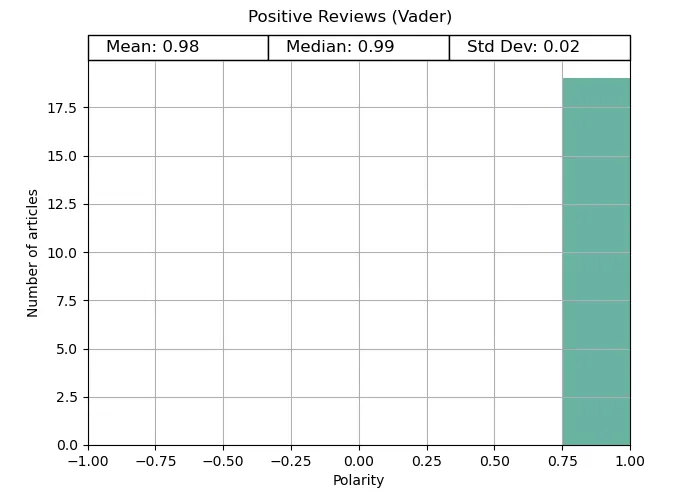
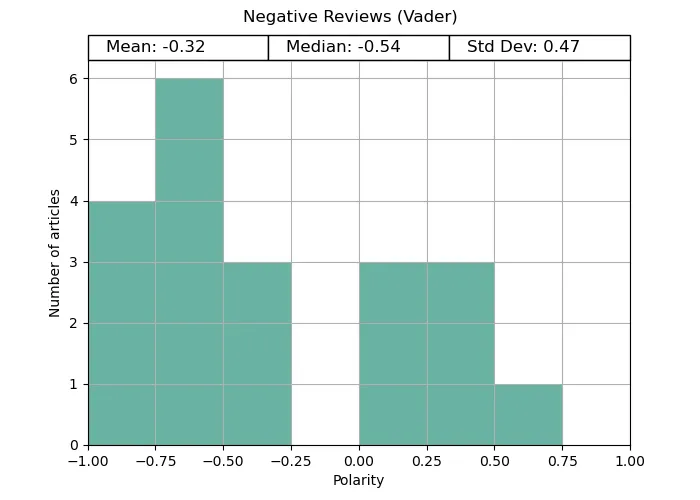
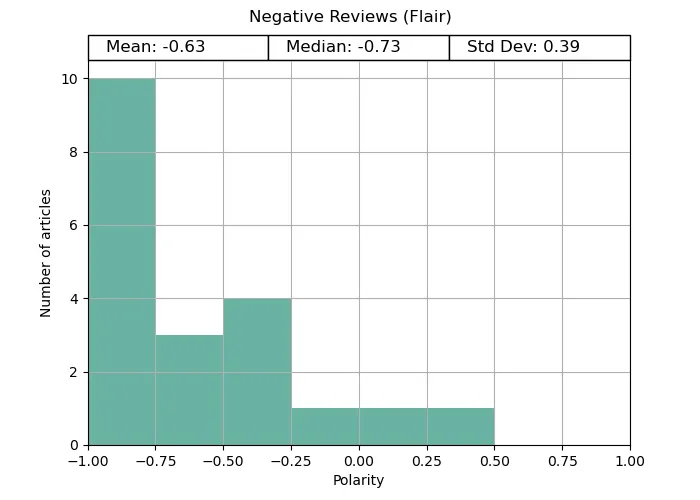
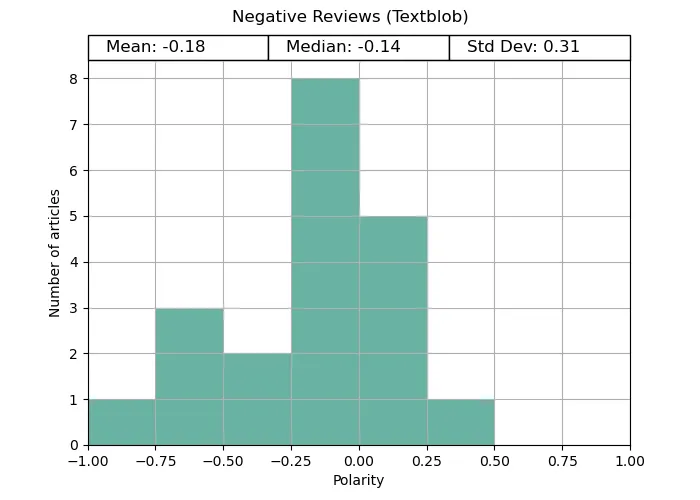
Vader gets full marks for the positive reviews, correctly identifying the polarity for every review. However, its negative review analysis was mixed. Although the average was negative, it was far less reliable.
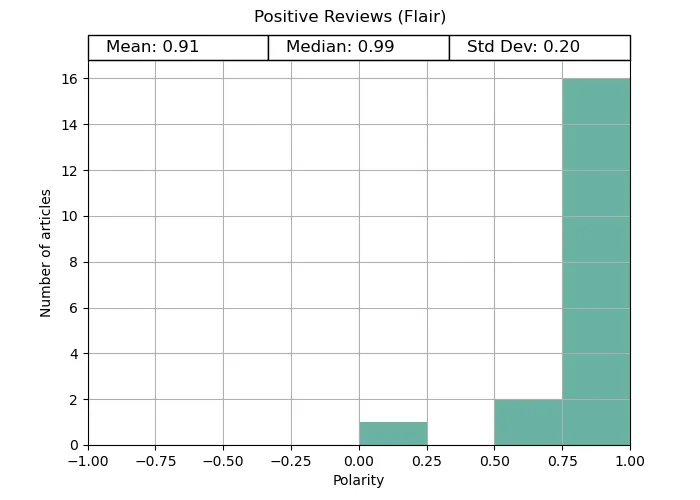
Flar provided expected results for both review cases and produced the correct analysis for more reviews than Vader.
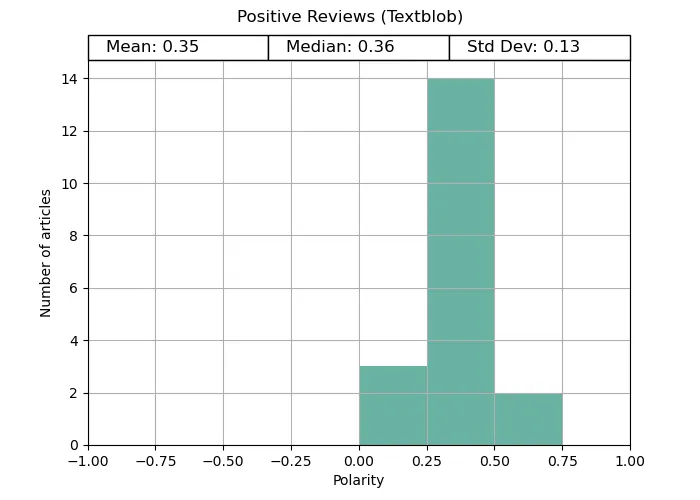
TextBlob did slightly better on this than for the articles section, but was still outshone by both alternatives.