LINKS
You can find the published rest-ai package on PyPi.
The code for the REST AI package can be found on GitHub.
ABSTRACT
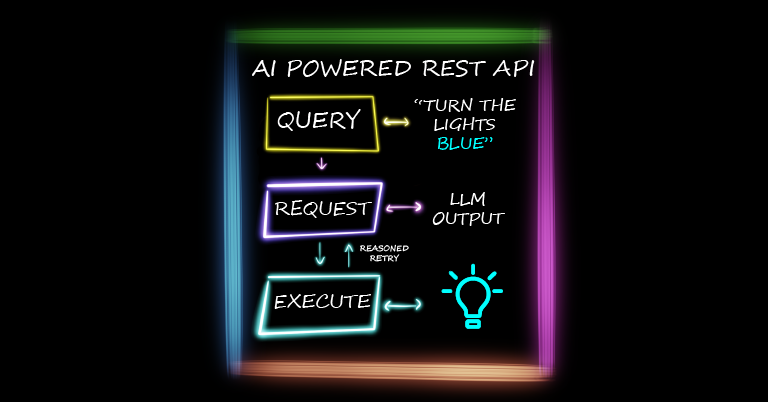
A Python package was published which allows users to invoke REST commands using LangChain ChatModels.
A reasoned retry logic loop was implemented, allowing the program to use errors and previous requests to ‘fix’ future requests.
The result was successful: the API for an LED strip was used as a test, and the package parsed the user’s request into suitable commands (e.g. pulse, clear, solid) with valid payloads. Many of the invalid REST AI queries were successfully retried, but using lower parameter chat models failed more regularly.
CONTENTS
DETAILS
A REST API is a set of rules that allows applications to communicate over HTTP. There is a standard set of methods, known as verbs, which instruct the application what to do (e.g. GET, POST, DELETE etc.).
Information needed for the request can be passed using parameters or message bodies. These APIs are very widely used in service and web development.
Most REST APIs have a schema defining how you can interact with the service and what to expect in return. It describes each available endpoint and the format of the data it needs.
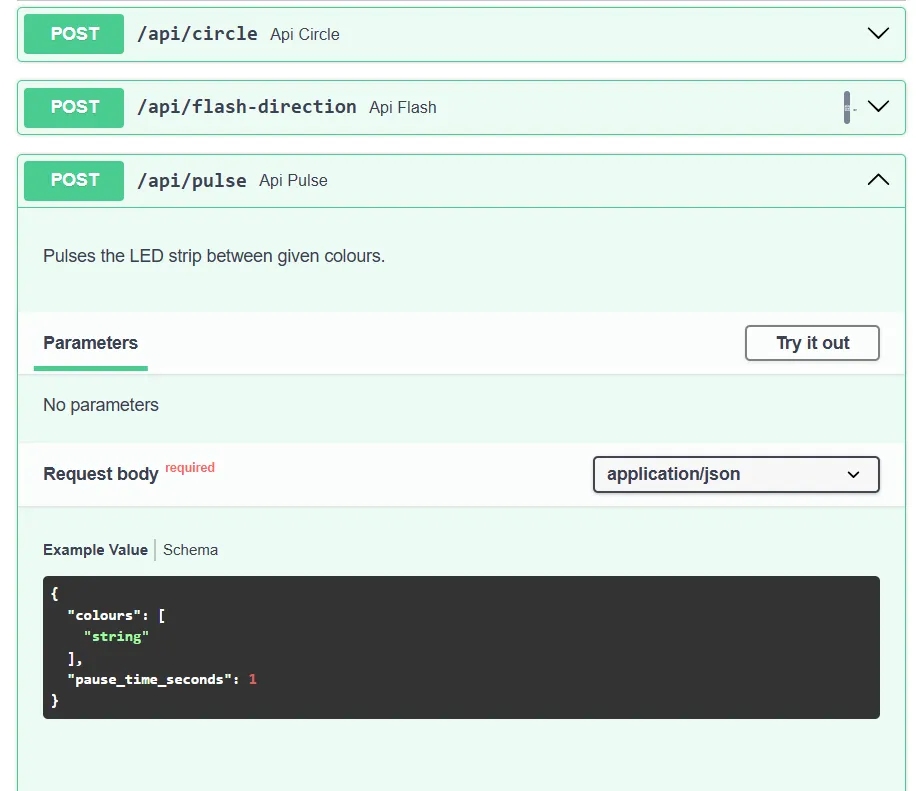
As an example, we can look at the REST API I made for my Smart Mirror LED Strip. The raw JSON can be found here, but Swagger provides a nicer way to view it.
These APIs are incredibly useful for interactions with or between services. However, the interactions follow a strict format, usually explicitly defined for whatever is calling the code.
We already know generative AI can be a powerful tool to help understand a user’s request. With the introduction of structured outputs from LangChain, we will look at REST AI Queries, and how effective the combination can be.
IMPLEMENTATION
Inputs
First, let’s consider the inputs of our AI REST query package.
We need the schema for the service, commonly known as an openapi specification.
We also need details of the service; we will keep things simple and have just the base_url. We can add headers or authentication later if needed.
Finally, we will need the base ChatModel. We want predictable outputs, so we will set the temperature of this to 0.
Logic
There are two main tasks we are completing when hitting invoke, extracting the request, and executing it.
The extraction is the main goal of the package. We want something that can be used to call a REST endpoint, so we make the following Python model
from pydantic import BaseModel, Field
class RestRequest(BaseModel):
"""Core data model for the REST AI Query"""
verb: str = Field(
description="HTTP verb to use for the request",
examples=["GET", "POST", "PUT"],
default="GET",
)
query_path: str = Field(
description="Path to use for the REST request", examples=["/api/v1/users"]
)
body: dict | None = Field(
description="A set of key values to send in the body of the request taken from the openapi spec. Set to None if not applicable",
default={},
)
query_params: dict | None = Field(
description="A set of key-values to send in the query taken from the openapi spec. Set to None if not applicable.",
default={},
)A couple of notes:
- The description is important, as it helps the LLM determine what field matches both your request and the openapi spec
- Examples can be useful but are a double-edged sword: I found that adding too many biased the LLM to using only the examples provided rather than coming up with its own
- If the LLM cannot parse the request strictly into the model, the application will fail. That is why the verbs is a string rather than an enum of all possible cases: we have to be loose with the class (e.g. allow for lower case letters)
Two simple prompts were used and chained with the above model to create a structured output model:
from langchain_core.prompts import PromptTemplate
rest_prompt_template = PromptTemplate.from_template(
"""
Create a valid REST API request based on the user's query. Use the openapi_spec provided to provide the method, query, body and parameters.
query: {query}
openapi_spec: {openapi_spec}
"""
)
rest_prompt_template_with_error = PromptTemplate.from_template(
"""
Create a valid REST API request based on the user's query. Use the openapi_spec. A previous request was made and it resulted in an error. Use the error message to correct the request.
query: {query}
previous request: {previous_request}
previous_error: {error}
openapi_spec: {openapi_spec}
"""
)The REST AI package will first try to use the rest_prompt_template. If the response is not successful, it will use the rest_prompt_template_with_error for subsequent tries until its max retry count is reached (defaulted to 3).
EXAMPLES
AI-Powered LED Strip
I tested the package with the LED strip API and the llama3.2 3b model running locally.
Below is a script I used to load the REST AI package and all of its inputs.
from rest_ai import RestAi
import json
import logging
import sys
from langchain_ollama import ChatOllama
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
base_url = "http://0.0.0.0:3001"
file_path = "/path/to/openapi.json"
with open(file_path, "r", encoding="utf-8") as file:
openapi_spec = file.read()
openapi_spec = json.loads(openapi_spec)
base_model = ChatOllama(
base_url="localhost:11434",
model="llama3.2:3b",
temperature=0,
)
rest_ai = RestAi(base_url, openapi_spec, base_model)
while True:
user_input = input("Enter query ('exit' to quit): ")
if user_input.lower() == 'exit':
break
response = rest_ai.invoke(user_input)
if response:
print("Response: ")
print(response.json())A simple request for clearing the strip:
Enter query ('exit' to quit): Clear the lights
INFO:httpx:HTTP Request: POST http://localhost:11434/api/chat "HTTP/1.1 200 OK"
INFO:root:Parsed query: verb='POST' query_path='/api/clear' body={} query_params={}
INFO:root:Response: {"message":"Clearing."}
Response:
{'message': 'Clearing.'}
Enter query ('exit' to quit): exitReasoned Retry
When asked to pulse between two colours, it took two attempts. In the first, the colours were not provided in the body, so this error was used to generate a new successful request:
Enter query ('exit' to quit): Pulse the lights between red and green.
INFO:httpx:HTTP Request: POST http://localhost:11434/api/chat "HTTP/1.1 200 OK"
INFO:root:Parsed query: verb='post' query_path='/api/pulse' body=None query_params=None
INFO:root:Response: {"detail":[{"type":"missing","loc":["body"],"msg":"Field required","input":null}]}
INFO:root:Retry Attempt: 1
INFO:httpx:HTTP Request: POST http://localhost:11434/api/chat "HTTP/1.1 200 OK"
INFO:root:Parsed query: verb='post' query_path='/api/pulse' body={'colours': ['#FF00A6', '#00C8FF'], 'pause_time_seconds': 1} query_params=None
INFO:root:Response: {"message":"Pulsing."}Speech to text
I also added a Speech Recognition layer ahead of the example so I could control it by voice.
CONCLUSIONS
The published REST AI package was successful, despite being run on a low parameter local model.
The reasoned retry logic worked better than expected, allowing the package to identify issues and fix them dynamically.
Potential improvements:
- Extend the request execution capability (e.g. headers, authentication, pre-hooks)
- Make the AI chain more efficient
- Experiment with different base models
Contributions to this project are welcome if you are interested!