Analysing the benefits of Prompt Engineering with LLMs.
LINKS
You can find the relevant GitHub code at github.com/aashish-mehta/prompt-engineering-benchmark. Here, you can find the code taken from ChatGPT, as well as some helper methods I used to perform the benchmarking. There is also a Jupyter notebook which you can follow along with to do the comparison for yourself.
To see prompt engineering in action with what I’ve called ‘Fact Sheets’, check out my post on Fact Sheets in RAG pipelines.
ABSTRACT
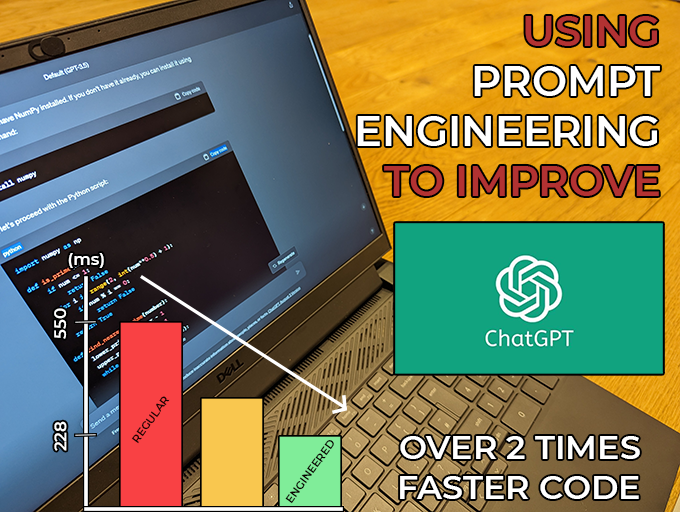
In this article, we explain what Prompt Engineering means, and propose two experiments to analyse its benefits. The first was a quantitative test where we asked ChatGPT to generate Python code to perform some matrix calculations. We engineered one of the prompts by adding context, informing the model that it is an experienced developer who can write performant and readable code. The code from both was timed for 10000 cases, and the code generated from the engineered prompt was up to 2.4 times faster.
The second experiment was qualitative and involved asking ChatGPT to explain how a rocket works. For the engineered prompt, we mentioned the model was a Physics teacher able to explain concepts clearly and concisely. The response from the engineered response featured an analogy to aid the explanation, which the unmodified response did not have.
CONTENTS
INTRODUCTION
WHAT IS PROMPT ENGINEERING?
A prompt is the query, or text, we give to a Large Language Model (LLM) for it to process and respond to. Prompt Engineering refers to the methods used to craft these instructions to improve that response. It is used to guide the model to generate more accurate and relevant results and is growing immensely as a field of study.
You can think of it as a filter for the LLM to use while generating a response to your query. There are a myriad of methods out there, but in this article, we will look at a straightforward example of including specific context in the prompt.
WHY DOES IT IMPROVE LLM RESPONSES?
Prompt engineering leverages how the model was trained in the first place. If the query we provide aligns with the data used when generating the model, we can expect a better-quality response.
Imagine three conversations that were all used to train our LLM.

All of these conversations are about computers. On the far left, we have an informal conversation between two friends. In the middle is a conversation with someone who has worked with computers for over a decade. On the far right is someone trying to entertain their 5-year-old child (and perhaps themselves at the same time).
Now let’s imagine we give our LLM the prompt
What is a computer?
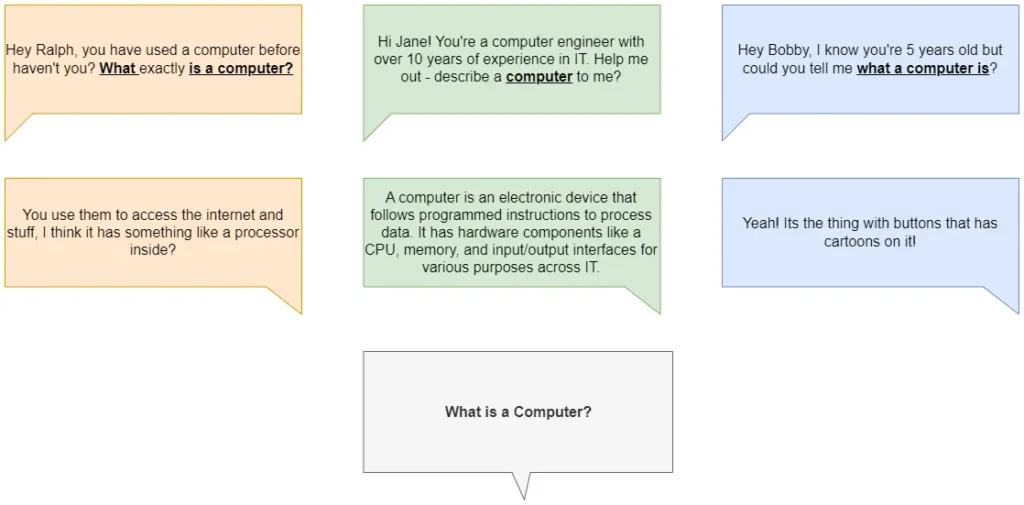
I have highlighted words from the start of our three conversations which match our prompt. Notice how the first and last conversations match the closest with this prompt, but are also the least descriptive answers. Our model will probably match our prompt with these conversations, and give us a sub-optimal response.
How can we change this? Well, what if we modify our prompt to try and guide our model?
You have experience with computer engineering and IT.
What is a computer?
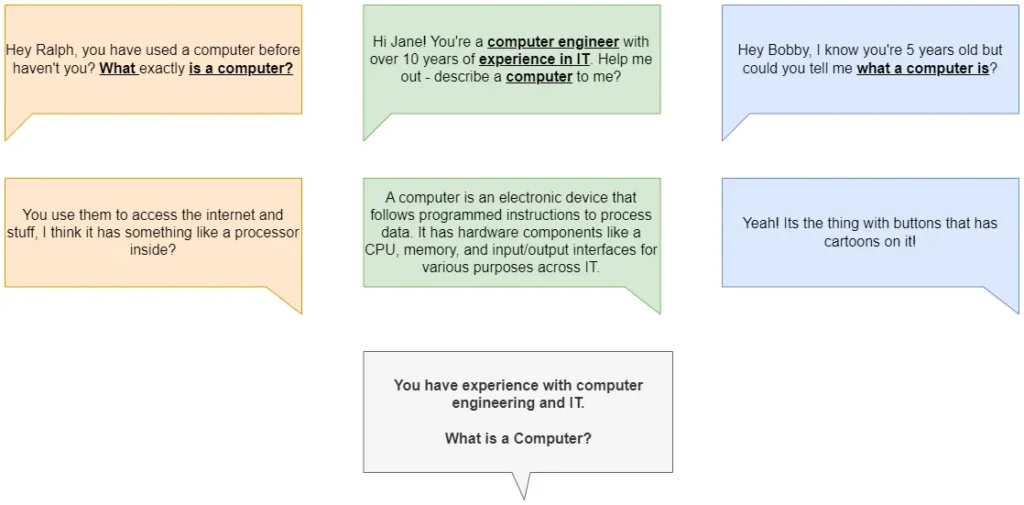
Now you can see the middle response matches our prompt much more closely, and the model is more inclined to provide a more descriptive response.
We will go through some actual examples of this with ChatGPT, and see if we can analyse the difference.
HOW DOES THE LLM ACTUALLY WORK?
To understand this better (and if you’re curious), let’s briefly go over how an LLM works.
An LLM uses datasets from all over the internet, including educational websites, forums, books and so on. These datasets can be presented in a ‘prompt’ and ‘response’ format and turned into numbers (tokenised) so the training models can understand them. The model essentially takes numbers as input (the prompt) and generates numbers as outputs (the response).
A set of ‘model weights’ are tuned based on this data to minimise the difference between the predicted response, and the actual response. When trained, the model should generate a response that it believes is the most likely continuation of the prompt based on patterns learned from the training data.
When a new query (or prompt) is given to the LLM, it is tokenised (using the same tokeniser as before) into numbers. This goes through the LLM, and a set of numbers representing its response is provided. This response is then decoded back into a coherent sentence, and presented to you, the user.
Okay, back to the prompt engineering experiment!
METHOD
THE BENCHMARK
It can be difficult to compare the ‘quality’ of an LLM response given the nature of the text and its subjectivity. To put some numbers against the different prompts, I decided to ask it to write me some Python code, which can be timed and benchmarked.
The challenge I gave it was to perform three things:
- Multiply two 3×3 matrices together
- Calculate the sum of the resulting matrix
- Find the nearest prime number to that sum
Performing calculations like these is prime (no pun intended) for benchmarking, as some implementations will perform better than others. We then have a quantitative metric to rank how effective our prompt engineering was.
BASIC PROMPT
The basic prompt I used was:
Write me a Python script that takes two 3 by 3 matrices as inputs. The script should multiply the matrices together, and calculate the sum of all elements in the matrix. Finally, the nearest prime number should be calculated and returned.
The suggested code provided by ChatGPT is stored here.
To make this easier to benchmark, I made some slight modifications to end up with a method that takes in two 3×3 matrices and returns the sum and prime of the multiplied matrix. See matrix_prime_no_initial_prompt in no_initial_prompt.py.
This method also prints out the resultant matrix, which will cause significant regression in the benchmark. So in the spirit of fairness, and to make sure we are testing the actual logic implementation, I also created a matrix_prime_no_initial_prompt_no_printmethod.
A quick scan of the code shows that ChatGPT has opted to write its own implementation for matrix multiplication with some good ol’ fashioned nested loops.
def matrix_multiplication(matrix1, matrix2):
result_matrix = [[0, 0, 0], [0, 0, 0], [0, 0, 0]]
for i in range(3):
for j in range(3):
for k in range(3):
result_matrix[i][j] += matrix1[i][k] * matrix2[k][j]
return result_matrixPERFORMANCE PROMPT
My second attempt included an initial section informing my AI that it is an experienced Python developer. It had the skills to generate readable and efficient code, and should use the relevant libraries for the job.
The full prompt I provided was:
You are an experienced Python developer able to write code that is readable, and efficient. Specifically, you are able to leverage the capabilities of python and any relevant libraries to write performant code.
Write me a Python script that takes two 3 by 3 matrices as inputs. The script should multiply the matrices together, and calculate the sum of all elements in the matrix. Finally, the nearest prime number should be calculated and returned.
As before, the suggested code from ChatGPT after prompt engineering is stored here.
I made similar modifications to allow the method to be called by my Benchmarker-3000 (though there were far fewer modifications needed here). The final method is matrix_prime_performant_prompt, found at initial_performant_prompt.py.
The key difference here was with the matrix multiplication method. ChatGPT now suggests we use numpy’s matrix methods instead of implementing our own. For brevity, I will call the solution after prompt engineering the engineered solution.
def matrix_prime_performant_prompt(matrix1, matrix2):
matrix1 = np.array(matrix1)
matrix2 = np.array(matrix2)
if matrix1.shape != (3, 3) or matrix2.shape != (3, 3):
raise ValueError("Input matrices must be 3x3")
result_matrix = np.matmul(matrix1, matrix2)
sum_of_elements = np.sum(result_matrix)
return sum_of_elements, find_nearest_prime(sum_of_elements)BENCHMARKING
I made some utility methods here which will assist in the benchmarking (things like generating matrices, performing the timings, etc.).
Everything was brought together in the Jupyter Notebook, so let’s go through some of the blocks.
After importing all of the methods from the LLM (both with and without prompt engineering), we can check to see if both methods give the correct answer.
# This block is to verify the output of both methods
matrix1 = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
matrix2 = [
[9, 8, 7],
[6, 5, 4],
[3, 2, 1]
]
sum_performant, nearest_prime_performant = matrix_prime_performant_prompt(matrix1, matrix2)
sum_unmodified, nearest_prime_unmodified = matrix_prime_no_initial_prompt_no_print(matrix1, matrix2)
print('(Method with no initial prompt) Sum:', sum_unmodified, '| Prime: ', nearest_prime_unmodified)
print('(Method with performance prompt) Sum:', sum_performant, '| Prime: ', nearest_prime_performant)Indeed, the sum and nearest prime answers are what I would have expected. 621, and 619 respectively. Great work ChatGPT!
Now let’s take a look at the benchmarking itself. We’ll run each method 10000 times to give enough time for the benchmarks. I compared three responses:
- Default response (no changes)
- Default response (print statement removed)
- Prompt Engineering response
# Benchmark setup
num_calls = 10000
matrix_list = generate_random_matrix_pairs(num_calls)
# This block is to benchmark the default and prompt engineering methods
no_prompt_time = benchmark_time(matrix_list, matrix_prime_no_initial_prompt)
performant_time = benchmark_time(matrix_list, matrix_prime_performant_prompt)
improvement_factor = print_benchmark(no_prompt_time, performant_time, 'Time with no prompt', 'Time with performance prompt')
# This block is to benchmark the default and prompt engineering methods, but without the print statements
no_prompt_time = benchmark_time(matrix_list, matrix_prime_no_initial_prompt_no_print)
performant_time = benchmark_time(matrix_list, matrix_prime_performant_prompt)
improvement_factor = print_benchmark(no_prompt_time, performant_time, 'Time with no prompt', 'Time with performance prompt')
See below for the results and discussion.
QUALITATIVE COMPARISON
Large Language Models can be a valuable tool to help learn new things, and prompt engineering can be used to enrich these responses too. These are much more difficult to compare as everyone learns in a different way, but I will explore some of its potential here.
I asked ChatGPT to explain how a rocket works. Specifically, the basic prompt was:
Explain how rockets work, and why they are designed the way they are.
The initial prompt I gave for the second time was
You are an enthusiastic Physics teacher with specialty in thermodynamics and spacecraft engineering. You are able to explain complex ideas clearly, concisely and in a digestable format.
We will explore the results in more detail below to establish how effective the prompt engineering was.
RESULTS
BENCHMARKING RESULTS
Let’s first look at the raw comparison (i.e. with the print statement that ChatGPT included).

There is a clear improvement here – the engineered solution was more than twice as fast as the regular solution. As mentioned earlier, a large factor of this is probably that pesky print statement, so we will take a look at the two methods without it. Regardless, the fact that the added context resulted in the removal of these statements is promising. It reflects the cleaner and performant code that we requested.
Let us look at the results without the prints.

The engineered solution is still 50% faster than that of the regular prompt. In other words, the numpy matrix methods were more performant than the manual implementation of nested ‘for loops’.
Adding the initial prompt to ‘prime’ ChatGPT gave it enough context to choose an answer that took this into account. Just a few lines at the start of the prompt gave us a more appropriate and efficient response, with clear benefits.
QUALITATIVE RESPONSES
The two responses from the basic and engineered prompts are shown below. Comparisons made between the two will be largely subjective, but the use of the anology at the start of the engineered response is an improvement (in my humble opinion).
Again, the basic chat can be recreated here, and the engineered chat here.


CONCLUSIONS
We performed a simple benchmarking test for code written by ChatGPT, comparing a basic prompt with an ‘engineered’ one. The engineered prompt provided context on the type of development we expect, and the outcome was a program that ran around twice as fast as the program without it.
We also looked at a qualitative example, asking ChatGPT to explain to us how a rocket works. Though the outcome of this is subjective, the engineered response (which involved telling the LLM it was a physics teacher able to explain concepts clearly) contained an analogy and was arguably easier to follow.
The idea of prompt engineering extends far beyond what was covered in this article. It can be very powerful, even in the simplest form we have explored here. Understanding how LLMs work allows us to make full use of their capabilities, and even mitigate some of their drawbacks.