Make your very own LLM assistant
LINKS
You can follow along using the code on GitHub: https://github.com/aashish-mehta/fact-sheet-rag to end up with your own personal AI assistant.
Also, see my post about Fact Sheets, and why they are useful in RAG architectures for some more context (no pun intended …).
ABSTRACT
We use the concept of a Fact Sheet to store information that would be relevant to a Large Language Model (LLM) like ChatGPT. The Fact Sheet contained statements stored either in a free-text file or a proposed JSON structure. It was then provided to the model as context enabling it to become a personal AI assistant. Initially, we pasted the facts into ChatGPT and asked it to use the context when answering questions. This was successful; the answers were tailored to the information we provided, and it could verify the response by providing the ID of the fact used.
Next, I attempted to use a small local model (Llama3 7B) with LangChain to load the Fact Sheet as documents in a Retrieval Augmented Generation (RAG) pipeline. Despite the small model, the resultant personal AI assistant could select and respond with the correct Fact and ID in response to my queries.
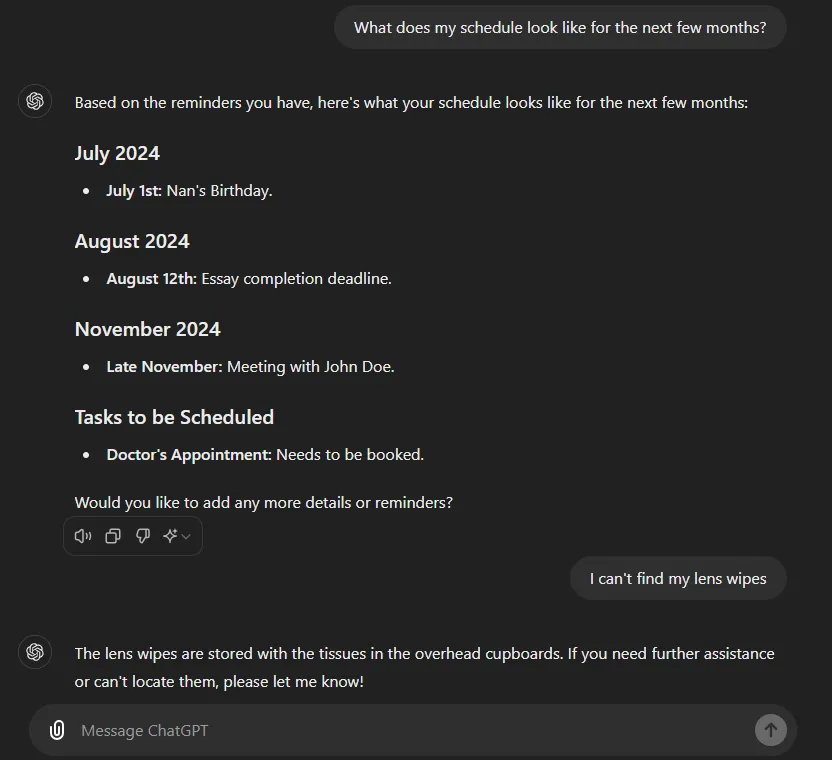
Those pesky lens wipes won’t be able to hide from me any longer!
CONTENTS
INTRODUCTION
LLMs have been making waves as great tools to help people plan, learn, organise and so much more. For good reason too, they’re amazing at turning human language into logic.
However, all wide-stream chat models have one issue: they are trained and loaded with generic data. They aren’t tailored to you so in their raw state, they are not useful as a ‘personal assistant’ that you can use daily. Ask ChatGPT where you put your spare tissues, and the poor model will scramble to list all the places they could possibly be in the world. So, how exactly can we get a personal AI assistant from ChatGPT?
In an earlier post, I explored the benefit of prompt engineering, and how it can provide effective context to get better responses from an LLM. We will be doing something similar here, providing personal context to our models using things called ‘Fact Sheets’.
A Fact Sheet is essentially just a set of information that the model can refer to when answering your question. They can be grouped (for example, reminders, events, a shopping list) and structured to make modifications and retrievals easier. The easiest way to get started is using free text to provide these facts directly to the model. I later experimented with a JSON structure to store these facts, which makes storing and updating them much easier. We will be using both in this article.
First, we will go through the steps of creating a Fact Sheet (both as Free Text and JSON). Next, we will show how these can be used with ChatGPT to instantly turn it into our very own personal AI assistant. I will also provide a summary of how to use it with LangChain on a local model served by Ollama, but more on that in another article (stay tuned!)
METHOD AND RESULTS
Creating a Fact Sheet
The updated steps for producing a Fact Sheet will be on the GitHub project’s README, but I will provide a complete set of instructions below.
Free Text
Creating a Free Text fact sheet is simple. You just have to write out your information in a .txt file, using a new line for each new fact.
I have to book a doctors appointment.
I have a meeting with John Doe in late November.
The essay has to be completed by October 14th.Save the file based on the type of facts you’ve provided (e.g. reminders.txt) and you’re done! I find that using concise language with imperatives works well. Remember, these are being turned into tokens for the LLM to understand and use for its output, so you want them to be relevant.
JSON
The JSON structure I use in these examples looks like this:
{
"reminders": [
{
"content": "I have to book a doctors appointment.",
"timestamp": "2024-06-30T12:21:36.704720",
"id": "msqsh79119le5ynl"
},
{
"content": "I have a meeting with John Doe in late November.",
"timestamp": "2024-06-30T12:21:36.704720",
"id": "pk4hx64s707vh4jx"
},
{
"content": "The essay has to be completed by October 14th.",
"timestamp": "2024-06-30T12:21:36.704720",
"id": "zq5xlb2rq1k7aq90"
}
]
}contentis the description of the fact.timestampis when the fact was created in ISO 8601 standard (to help with auditing and provide some additional context).idis a 16-digit alphanumeric string which can be used to track facts, and know ‘where’ the LLM got its answer from.
You can turn any Free Text Fact Sheet into a JSON structure using the convert-facts-to-json.py script, and see an example of a full JSON Fact Sheet here.
Using the Fact Sheet with ChatGPT
Both the Free Text and JSON Fact Sheets are used to prompt ChatGPT to be a personal AI assistant in the same way – copying and pasting it with the following:
The following is a list of facts which you should use as context for my questions. The goal is to be a personal AI assistant.
[[FACT SHEET]]

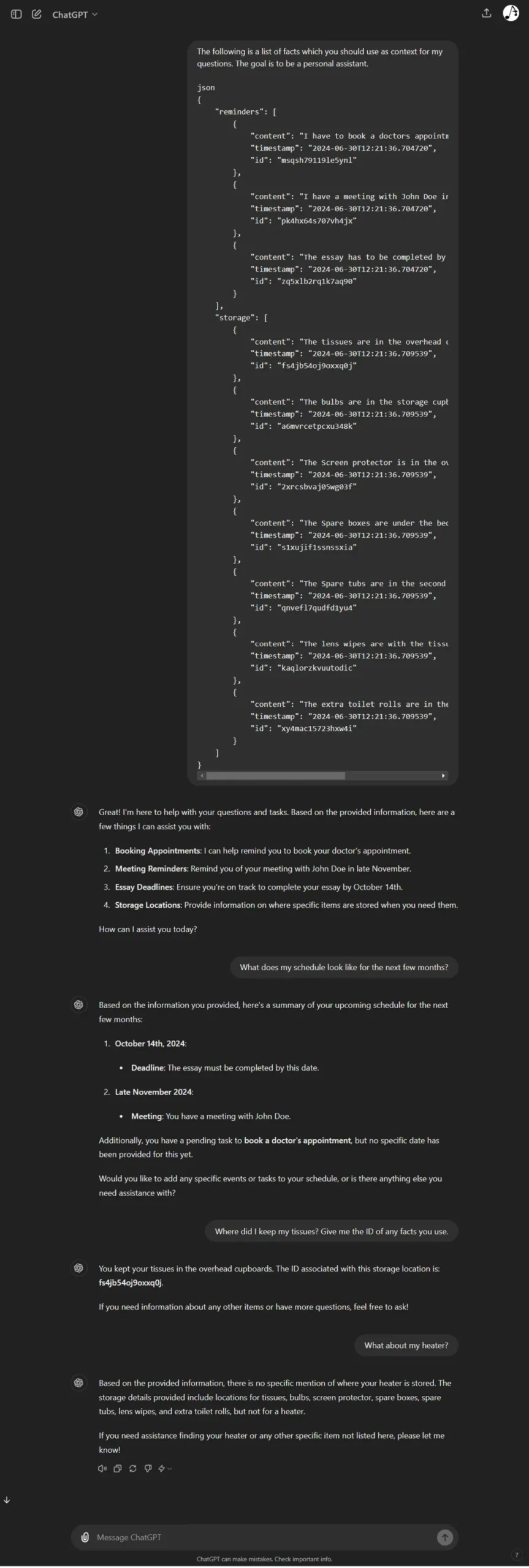
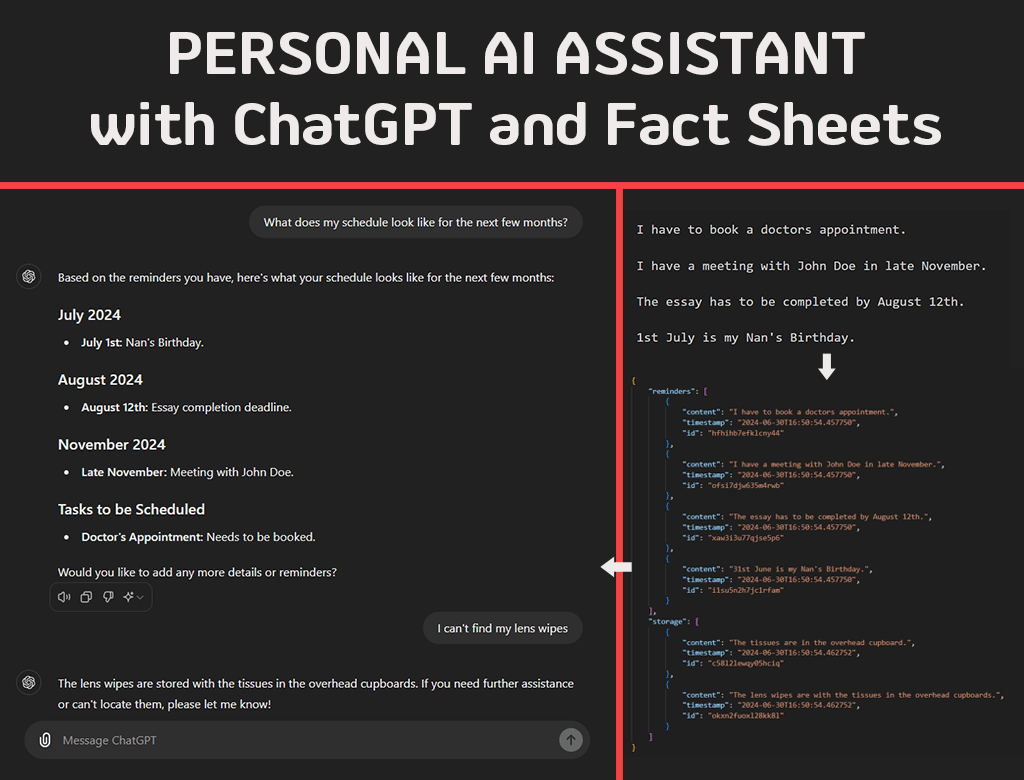
In both examples, we can ask ChatGPT about what our schedule looks like, and where things are stored based on what we mentioned in the Fact Sheet. Also note that when we ask a question about something that isn’t in the Fact Sheet, it explicitly states so, and does not try to answer.
In the JSON Fact Sheet example, we can also ask for the Fact ID(s) it used to get the response, which is extremely useful for verification.
The biggest issue with this will be the size and relevance of the context. As we ask more and more questions, the number of tokens sent to our LLM will increase and get closer to hitting the limit of its context window (how many tokens a model can take as an input). More importantly, the tokens in its provided context will include the chat history between you and the model. While this is great for mimicking natural conversation (something any personal AI assistant needs …), it puts less priority on the initial ‘Fact Sheet’ we provided, making it more likely to hallucinate.
This is where concepts like Retrieval Augmented Generation (RAG) come in. We can create a ‘database’ of information which is accessible to the LLM for each query.
Let’s explore this a little more by providing our Fact Sheets as documents in LangChain.
Using the Fact Sheet with LangChain
I put together a quick Jupyter Notebook which goes through the steps of loading up an Ollama model, setting up the LangChain pipeline, and loading in the Fact Sheet either in JSON, or a directory of Free Text files.
In a nutshell, we will be converting and storing our Fact Sheets in Vector Databases, which store data as vector embeddings (bits of data with semantics encoded, so they can be used to find themes and similarities throughout the content). When we provide a question to our LLM, it will query this database to extract relevant parts and provide it alongside our query.
To load in Free Text Documents, I used LangChain’s directory loader pointed to the text files we created earlier:
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader('./fact-sheets-txt', glob="**/*.txt") # Documents for your Personal AI Assistant
docs = loader.load()To load in JSON documents, I used the JSON loader instead:
from langchain_community.document_loaders import JSONLoader
file_path='./facts.json' # Documents for your Personal AI Assistant
loader = JSONLoader(
file_path=file_path,
jq_schema='.',
text_content=False)
docs = loader.load()To see the full code, check out the Jupyter Notebook I linked above. In it, we turn the documents into embeddings, store them in the vector database, and create a Q&A retrieval chain which uses our Fact Sheet. This final chain is our own local, personal AI assistant.
Here is the output using a Llama3 (7B) model running on my local machine:

We get an initial warning about the number of elements in the index – this is because we’ve only provided one document acting as our Fact Sheet. This number would increase if we had more sheets or separated the JSON into smaller chunks.
Regardless, the little model did its job in letting me know where the tissues are and the fact ID I can use to verify it (so I can watch Coco in peace.)
CONCLUSIONS AND FUTURE WORK
We have proven that Fact Sheets can be used to seed information to LLMs, turning them into effective personal AI assistants. The free-text format was the quickest and easiest way to get started and provided enough context for the model to perform well as an assistant. It successfully extracted the correct fact to use in its response and did not hallucinate when a question was asked for which no fact was provided.
When we converted the facts into a JSON structure, we benefited from the additional id field which allowed us to verify the model’s response. We also provided a timestamp field which provides an audit trail for additions and modifications (and can potentially be useful context for the model)
Using Llama3 7B locally also provided promising results. LangChain’s document loaders worked well to provide context from both the free-text and JSON Fact Sheets.
Some areas I would like to explore moving forward are:
- Providing Fact Sheets with more content
- Updating the Fact Sheets on the fly (served through a database) and reloading the LLM’s context
- Leveraging function calling to allow the LLM to update the Fact Sheet
- Implementing voice recognition and response with the RAG chain
Thank you for reading the article, let me know how you think we can improve the concept of a personal AI assistant even further!