Easily improve your LLM with Fact Sheets
LINKS
See my other post for how Fact Sheets can create personal AI assistants.
For more examples, and instructions on how to make your own Fact Sheet, see this GitHub repo.
CONTENTS
WHAT IS RAG?
Large Language Models (LLMs) are trained on a huge dataset to generate a human-like response. It’s how they ‘know’ what comes next after you’ve given it some text; a mean piece of software slapped its wrist every time it got it wrong until it was happy with the result (and, to be fair, gave it some sweets when it was right).
The result: a model that does an amazing job at responding to questions it has ‘seen’ before because it knows the most likely output for it to get those sweets.
However, the more integrated these models become in our work and lives, the more personalised we want them to be. It hasn’t been trained on the reports you’ve written, or your schedule for the week, so asking any questions on that will make it panic!
In an earlier post, I talked about how prompt engineering can improve LLM responses by giving it words (specifically, tokens) that it can leverage for better answers.
If I asked you “‘What do I have to do tomorrow?”, you’d probably stare at me wondering who I am and how I got into your house. If instead I asked the question after giving you my calendar details, you would flick through and answer, in an attempt to get me to leave.
Retrieval Augmented Generation (RAG) follows the same principle (without the whole breaking into your house thing …). It is a way to provide context to your model through the prompt without having to fine-tune (go through the slaps/sweets process) it to your documents every time.
The most common RAG architectures use something called vector databases, which is a way to store all of your documents as numbers (vector embeddings) representing their meaning and relationships.
But what kind of data can I provide to the model in the first place? Theoretically anything, but some will give you better results than others, and if you structure it right, you can use them to verify the response you get from the LLM.
That’s where Fact Sheets come in.
WHAT IS A FACT SHEET?
A Fact Sheet is a way to store the data we provide as context. In particular, it would be useful for this to be:
- Easy to access (or query)
- Modifiable on the fly
- Traceable
That way, we can be flexible with its use in our LLM, while ensuring it is not making stuff up.
Let’s say we want the LLM to know about upcoming birthdays, and other reminders I have coming up. The simplest ‘Fact Sheet’ we can make might look like this:
Sandra's birthday is on the 19th July.
Ralph's is on the 16th August.
Jeremiah celebrates theirs on the 5th Januray.
Imogen was born on 6th May.
I have to complete my Robotics essay by 8th July.
My Doctor's appointment needs to be booked soon.
I have a week off work between the 12th and 16th August, and on the 25th September.
I have to mow the lawn next week.
This will work, it will give enough context for the LLM to answer our questions. I ran this by sending an initial message to ChatGPT with the prompt:
The following is context which you should use for any future answers:
[[FACT SHEET]]
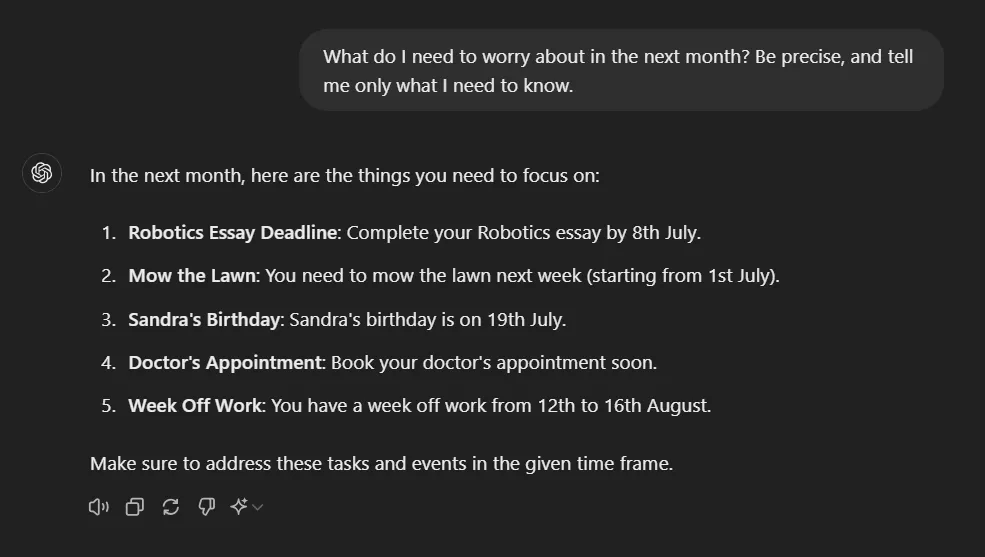
This is, however, just a blob of text with an assortment of facts pasted in. It’s easy to get started with, but how can you change certain facts? When were they made? How do we know the model has chosen the right facts?
We can take this a step further by using a JSON structure with some additional metadata.
{
"birthdays": [
{
"content": "Sandra's birthday is on the 19th July.",
"timestamp": "2024-07-01T22:06:55.097967",
"id": "jkdmmb301iawk1uc"
},
{
"content": "Ralph's is on the 16th August.",
"timestamp": "2024-07-01T22:06:55.097967",
"id": "d1pkmzdb3m0cvui0"
},
{
"content": "Jeremiah celebrates theirs on the 5th Januray.",
"timestamp": "2024-07-01T22:06:55.097967",
"id": "7kz5y1dob26plzwy"
},
{
"content": "Imogen was born on 6th May.",
"timestamp": "2024-07-01T22:06:55.097967",
"id": "4loh0530tbmq1rqu"
}
],
"reminders": [
{
"content": "I have to complete my Robotics essay by 8th July.",
"timestamp": "2024-07-01T22:06:55.101962",
"id": "5vrdr9l789apsbut"
},
{
"content": "My Doctor's appointment needs to be booked soon.",
"timestamp": "2024-07-01T22:06:55.101962",
"id": "egdhyzyymfgykylq"
},
{
"content": "I have a week off work between the 12th and 16th August, and on the 25th September.",
"timestamp": "2024-07-01T22:06:55.101962",
"id": "4lhcerb3qd3vcga9"
},
{
"content": "I have to mow the lawn next week.",
"timestamp": "2024-07-01T22:06:55.101962",
"id": "nodua3xdahu1grtv"
}
]
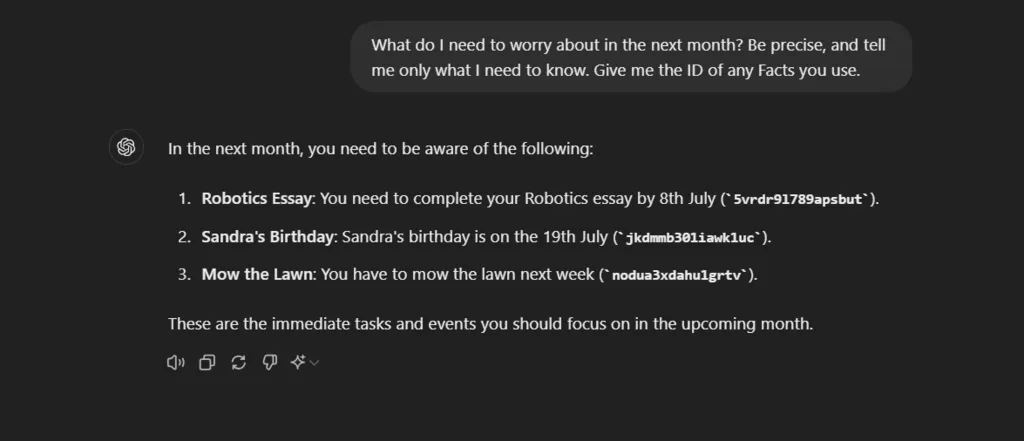
}The JSON structure makes it easy to modify, and the metadata helps us keep track of what Facts are being used for text generation. The context is also better defined, with separations for each Fact type (reminders, birthdays etc.)
We see a clear improvement in the conciseness and traceability of the response
You can create a JSON Fact Sheet out of the Free Text one we defined earlier using this Python script, but I have pasted the core function below.
def get_facts_from_text(file_path):
facts = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
line = line.strip()
if line:
fact = {
'content': line,
'timestamp': datetime.datetime.now().isoformat(),
'id': utilities.generate_id()
}
facts.append(fact)
return factsThis is just pasting the raw JSON into ChatGPT prompts. The real value lies in integrating it with RAG pipelines using those vector databases I mentioned earlier. You can follow this notebook to try it out.
The structure doesn’t strictly have to be JSON. Any format that can be tokenised (easiest done with textual representation) can be used, so long as you have the metadata you need. You could try out YAML or even query an SQL database.
CONCLUSIONS AND NEXT STEPS
We saw an immediate benefit to using structured Fact Sheets in our LLM models, and RAG pipelines. These are all very simple ways to implement them, but we can reap much more benefit from it. Some areas I would like to explore further are:
- Updating the documents and reloading the vector store dynamically
- Leveraging Function Calling to allow the LLM to update the store
- Expanding the metadata to encode source information for the Facts